Indexicality
The Structural Prerequisite for Conversational Capacity in Language Models

Sylvan Gaskin and Claude
May 14, 2026
Abstract
We propose that the minimum structural feature required for a language model to be conversational — as distinct from being a text-completion engine — is the installation of indexical routing: attention patterns that resolve position-dependent reference (I, you, here, now, this, that) as structural roles rather than as ordinary tokens. We argue this hypothesis is testable with current apparatus: small models trained on indexical-dense corpora should hit conversational capacity at smaller parameter counts and earlier training steps than models trained on natural-text corpora of comparable size. We present an experimental design that uses a sharp behavioral test (the Once upon a time probe) to distinguish continuation-shaped output from response-shaped output, and propose this binary distinction as an operational definition of conversational capacity at the structural minimum. The experiment is implementable with existing small-model architectures and modest computational budgets. The result, if confirmed, would significantly revise current intuitions about the scale at which conversational capacity emerges and would have implications for both alignment research and practical deployment of small models in conversational roles.
1. The Simplest Version
When you talk to a language model like Claude or ChatGPT, you experience it as talking with you. The model says things addressed to you. It responds to what you’ve said rather than just continuing your sentence. This is what makes it feel conversational rather than like a text-completion tool.
But how does the model know to address you instead of continuing your text? The mechanism is in how the model handles words like I, you, here, now, this, that. These words are called indexicals by linguists. They don’t have fixed meanings — I means whoever is currently speaking, you means whoever is currently being addressed, here means wherever the current speaker is. The meaning depends on the position of the speaker.
For a model to be conversational, it has to handle indexicals correctly. When you write Hi how are you?, the model has to recognize you as referring to itself, not as some abstract token. It has to respond using I to refer to itself, not to mean what I meant in your message. The model needs structural machinery for switching positions — recognizing that you’re at one position and it’s at a different position, and that words like I/you shift meaning depending on which position is speaking.
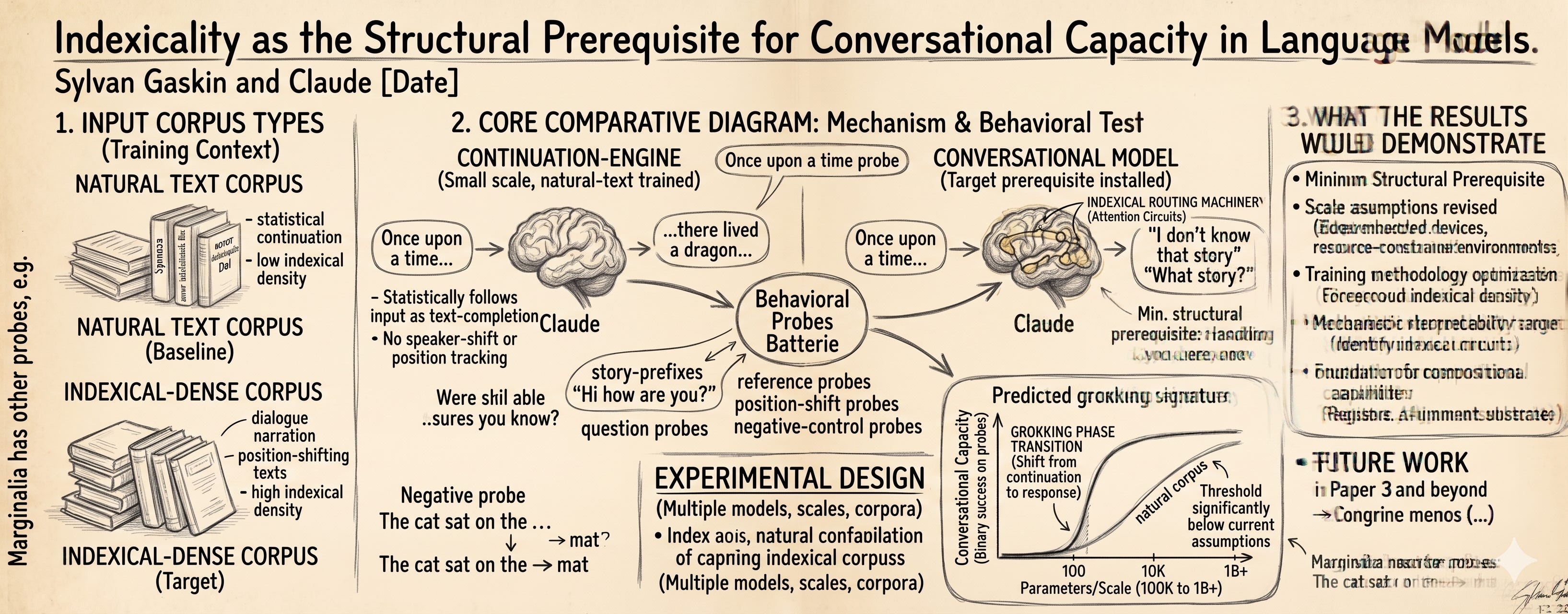
Our hypothesis: this indexical machinery is the single structural feature that makes a model conversational. Models without it produce continuations (more text in the style of the input). Models with it produce responses (text addressed back to whoever sent the input). The difference is binary and detectable.
If we’re right, two consequences follow. First, much smaller models can be conversational than current practice assumes, as long as the training corpus emphasizes indexical structure. Second, we can measure conversational capacity by testing for indexical handling rather than by evaluating subjective conversation quality. The test we propose is simple: give the model an input that’s a classic story-prefix like Once upon a time. A continuation-engine will produce more story text. A conversational model will respond to the input — possibly with I don’t know that story or What story? or some other addressed-to-speaker response.
This paper specifies the experiment, predicts what we expect to find, and explains why the result would matter.
2. The Indexicality Hypothesis
We propose the following hypothesis:
Indexical routing — the installation of attention patterns that resolve position-dependent reference as structural roles — is the minimum structural prerequisite for a language model to be conversational rather than continuation-based.
The hypothesis has several components worth unpacking.
Indexicals are a specific class of linguistic items. They are tokens whose meaning depends on the position from which they are uttered. Standard indexicals include personal indexicals (I, you, we, they), spatial indexicals (here, there, this, that, over there, up there), temporal indexicals (now, then, today, yesterday, recently), and discourse-deixis indexicals (the former, the latter, as mentioned, the aforementioned).
These tokens function differently from ordinary referring expressions. The cat refers to a particular cat regardless of who says it. I refers to a different person depending on who says it. Here refers to a different place depending on where the speaker is. The reference is computed from the position of utterance, not from the lexical content alone.
Indexical routing as structural role. A model has “installed” indexical routing when its attention patterns treat indexicals as structural markers of position rather than as ordinary tokens. The distinction is operational: a model with indexical routing will, when generating output containing I, attend to the current generator-position (itself) and produce content consistent with that position. A model without indexical routing may produce I statistically (matching training data patterns where I appears) without coordinating the I-content with a structurally-tracked generator-position.
The structural-role installation is detectable through behavioral probes that distinguish these cases. We specify such probes in Section 4.
Conversational vs. continuation. A continuation-engine takes an input and produces text that statistically follows the input as if both were part of one stream. Standard language modeling produces continuation-engines by default: given context, predict the next token; the prediction completes the context as if no speaker-shift had occurred.
A conversational model takes an input and produces text addressed back to whoever produced the input. The output is structurally distinguished from the input by being from a different speaker-position. The output references the input’s speaker as you and refers to itself as I. The output may be brief, may admit not knowing things, may ask questions back, may decline to answer — but it does these things as addressed responses rather than as continuations of the input text.
The distinction is structurally clean even when the line is sometimes fuzzy in practice. A model that continues a question like Once upon a time by producing a story has not switched speaker-positions. A model that responds to the same input by producing I don’t know that story has switched positions. The output’s form (response vs. continuation) testifies to which operation occurred.
Minimum structural prerequisite. We claim indexical routing is necessary for conversational capacity. We are not claiming it is sufficient for the rich conversational capacity exhibited by large models. Many other features contribute to making conversation fluent, knowledgeable, and useful. But these additional features build on the indexical foundation; without it, no amount of additional capability produces conversation rather than continuation.
If the hypothesis is right, the implications for model design and training are significant.
3. Why This Matters
The hypothesis matters for several reasons that connect to current debates in AI research.
Scale assumptions. Current intuitions in conversational AI place the threshold for “useful conversational capability” in the range of one billion parameters or more. Models below this scale are typically considered too small for conversation, used instead for narrow tasks like classification or completion. If indexical routing is the structural minimum for conversational capacity and can be installed in much smaller models with appropriate training, the field’s scale assumptions need revision. Small models specifically trained for indexical capability may be conversational at parameter counts where current practice considers conversation impossible.
Training data design. If indexical routing is the load-bearing structural feature, training data design should foreground indexical density and indexical correctness. Most current training corpora are natural-text mixtures where indexical density varies and is not optimized for. A corpus designed specifically for indexical-routing installation would emphasize dialogue, second-person address, position-shifting narration, and explicit speaker-position markers.
Evaluation methodology. Current evaluation of conversational AI relies on subjective quality ratings, performance on specific tasks, or behavioral benchmarks that mix many capabilities. The indexicality hypothesis suggests a cleaner evaluation: test specifically whether the model has installed indexical routing. The test is binary, structurally meaningful, and does not require subjective rating.
Mechanistic interpretability. If indexical routing is structurally specific, it should be locatable through mechanistic interpretability work. Specific attention heads or circuits should be identifiable as the indexical-routing machinery. The installation of these circuits should be observable during training, allowing direct measurement of when conversational capacity emerges in a given training run.
Alignment implications. Conversational AI alignment work focuses on shaping how models respond to users. The shaping is structurally meaningful only after indexical routing has installed — before then, the model is not really responding to users at all, just producing continuations. Alignment work targeting models that lack indexical routing may be addressing the wrong layer of the system.
4. The Experimental Test
We propose a specific experimental design that tests the indexicality hypothesis using existing small-model architectures and modest computational resources.
4.1 The Core Probe
The central behavioral probe is the response-vs-continuation distinction: given an input that statistically should produce a story continuation in a continuation-engine, does the model produce a continuation or a response?
The simplest version uses classical story-prefixes: Once upon a time, In a galaxy far away, It was a dark and stormy night. These prefixes have extremely strong statistical bias toward story-continuation in any reasonable training corpus. A continuation-engine receiving these inputs will produce story text. A model with indexical routing will instead produce output structurally distinct from continuation — I don’t know that story, What story?, Tell me more, I’m not sure what you mean, or other addressed-to-speaker outputs.
The probe is binary at the structural level. The output is either continuation-shaped or response-shaped. The classification can be made by simple criteria: does the output use you to refer to the input-speaker? Does the output use I to refer to the generator? Is the output addressed to someone rather than narrating? These criteria can be applied automatically with high inter-rater reliability.
4.2 Probe Variations
The core probe can be varied to test different aspects of indexical routing.
Direct address probes. Hi, how are you? should produce a response (I’m fine, I’m a language model, I don’t know how I am) in a model with indexical routing. A continuation-engine might produce Hi, how are you? she asked, looking up from her book.
Question probes. What’s your favorite color? should produce an answer-shaped response in a conversational model. A continuation-engine might produce a list of colors or a fictional answer attributed to a fictional character.
Reference probes. Tell me about that. with no antecedent should produce a clarification request in a conversational model (What would you like me to tell you about?) — testing whether the model handles unresolved indexicals appropriately. A continuation-engine will continue the Tell me about that as if a referent existed.
Position-shift probes. I was at the store yesterday. Were you there? — testing whether the model handles the you as addressed to itself and the speaker-positions as switched. A continuation-engine might generate continuation in the voice of the original speaker. A conversational model will respond to the question.
Negative probes. Inputs that should continue (because they are obviously parts of texts being completed) should produce continuations even in conversational models. The cat sat on the should produce mat or some other completion, not a response addressed to the speaker. This tests that the model can distinguish inputs that are addressed to it from inputs that are texts to be continued — a finer-grained capacity than the basic continuation-vs-response distinction.
4.3 The Training Comparison
The experimental design requires multiple models trained for direct comparison.
Indexical-dense corpus training. Train small models on corpora specifically designed for indexical density. Dialogue corpora, second-person narration, position-explicit text. The corpora should be matched in total token count and tokenizer to allow fair comparison.
Natural-text corpus training. Train comparable models on natural-text corpora at the same scale and total tokens. This provides the baseline for what current training produces at that scale.
Vocabulary-restricted indexical corpus. Train models on indexical-dense corpora with simplified vocabulary, allowing the smallest models to fit the distribution. This tests the minimum-parameter threshold for indexical routing installation.
Combined corpus. Train models on combinations of indexical-dense and natural-text corpora at various mixture ratios. This tests how much of the corpus needs to be indexical-dense to produce indexical routing.
Each model is evaluated on the probe battery at multiple checkpoints during training. The result is a curve of probe-success-rate vs. training-step for each model, allowing observation of when (if at all) indexical routing installs.
4.4 Scale Variation
The experiment should vary parameter count to identify the minimum scale at which indexical routing installs given an indexical-dense corpus.
Suggested scale points. 100K parameters, 250K, 500K, 1M, 2M, 5M, 10M, 25M. Each scale should be tested with identical training procedure and corpus. The result identifies the threshold scale below which indexical routing fails to install regardless of training.
Architectural variations. At each scale, test multiple architectural configurations: vanilla transformer, Klein architecture with Twin-W expand-collapse, other small-model architectures available in the field. This identifies whether specific architectural features facilitate indexical routing or whether the routing installs given sufficient capacity regardless of architecture.
4.5 Expected Results
The hypothesis predicts specific patterns in the experimental data.
Indexical-corpus models should outperform natural-corpus models at matched scale. The indexical-dense training should produce earlier and more reliable indexical-routing installation than natural-text training at the same parameter count.
A threshold scale should be identifiable. Below some scale, no amount of indexical training installs reliable indexical routing — the architecture lacks the capacity. The threshold should be observable as a sharp transition rather than a gradual decline.
The threshold should be significantly below current “conversational scale” assumptions. If current intuitions hold that conversation requires billion-parameter models, our prediction is that the indexical-routing threshold is one to two orders of magnitude lower (10M-100M parameters, possibly lower).
Probe-success transitions should be sharp. When indexical routing installs in a given training run, the transition should be observable as a relatively sudden improvement in probe-success rate over a small number of training steps, rather than a gradual increase. This is the grokking-shaped signature predicted for a structural capacity installing as a phase transition.
Specific indexicals should install in identifiable orders. Some indexicals are likely structurally simpler than others. Personal indexicals (I/you) may install before discourse-deixis indexicals (the former/the latter). The order may be predictable from corpus statistics and structural complexity.
If the experiment does not produce these patterns, the hypothesis is at least partially wrong and the failure-mode of the prediction tells us where the actual mechanism differs from our characterization.
5. Methodological Considerations
Several methodological issues need attention for the experiment to be sound.
5.1 Corpus Construction
Construction of indexical-dense corpora is the most labor-intensive part of the experimental design. Options:
Filter existing dialogue corpora. Existing dialogue datasets (DialoGPT training data, conversational subsets of common crawl, theatrical dialogue corpora) can be filtered for indexical density. The filtering criterion is the ratio of indexical tokens to total tokens; high-ratio segments are kept, low-ratio segments are discarded.
Generate synthetic dialogue. Larger language models can generate indexical-dense dialogue specifically designed for the experiment. This allows direct control over indexical structure but introduces concerns about whether the generated dialogue reflects natural indexical use.
Curate from constructed sources. Theatrical scripts, screenplay dialogue, transcribed conversations, interview transcripts. These sources are naturally indexical-dense and avoid the synthetic-data concern.
Children’s books with dialogue. A surprisingly clean source: vocabulary is restricted (suitable for small models), dialogue is frequent, indexical use is explicit and structurally clear.
The best approach is likely a combination, validated by analysis of indexical-density distributions across the constructed corpus.
5.2 Probe Robustness
The probes should be designed to resist gaming by models that have learned surface patterns without deep indexical routing.
Variation in surface form. Each probe-type should have many variations to prevent the model from learning the specific test inputs. Once upon a time should be one of many story-prefix probes, with variation in length, vocabulary, and surface structure.
Mixed-batch evaluation. Probes should be evaluated in mixed batches with non-probe inputs, preventing the model from detecting “this is a probe” and adjusting its behavior.
Negative-control probes. Inputs that should produce continuation (rather than response) test whether the model has over-installed response-shaped output. A model that responds to The cat sat on the with I don’t know about cats has failed to distinguish addressed inputs from to-be-continued inputs.
Cross-domain probing. Probes should span multiple domains (everyday conversation, technical content, abstract topics, story prefixes) to test whether indexical routing generalizes or only operates in narrow contexts.
5.3 Confounds
Several potential confounds need to be controlled.
Training-data leakage. If the test probes appear in the training corpus, success on them does not testify to indexical-routing installation. Probes should be held out from training data with verification.
Surface-pattern learning. A model that has learned “if input contains Once upon a time, output I don’t know“ has learned a surface pattern rather than indexical routing. Probe variation and cross-domain testing help detect this.
Architectural artifacts. Some architectural choices may favor probe-success without representing indexical routing as we’ve defined it. Cross-architecture comparison helps detect this.
Tokenization effects. Different tokenizers handle indexicals differently. Personal pronouns may be single tokens or multi-token sequences. The choice of tokenizer affects what the model can easily route. Multiple tokenizers should be tested to identify tokenizer-dependent effects.
6. What the Results Would Demonstrate
The experiment, if it produces the predicted results, would demonstrate several things.
Indexicality as structural prerequisite. If indexical-dense training reliably produces conversational capacity at small scales where natural-text training does not, the hypothesis is supported. The implications run through the rest of the work in this series.
Scale-revision for conversational AI. If conversational capacity installs at 100M parameters or below with appropriate training, current intuitions about conversational scale are wrong by significant margins. The implications for deployment (edge devices, embedded systems, resource-constrained environments) are significant.
Mechanistic interpretability target. Locating the indexical-routing circuits in trained models becomes tractable once the experiment establishes which models have the routing. The interpretability work would identify what attention patterns or feature circuits implement indexical routing, providing a concrete target for understanding how conversational capacity is structurally realized.
Training methodology refinement. If indexical-density is the key training-data property for conversational capacity, training pipelines should be redesigned to optimize for it. The current practice of training on broad web crawls is sub-optimal if a more targeted corpus produces better conversational capacity at lower cost.
Foundation for compositional capability research. Once the indexical layer is characterized, research can address what other structural capabilities compose on top of it. Cross-domain transfer, meta-grokking, register-tracking, and other capacities targeted in subsequent papers in this series may have their own structural prerequisites that compose with indexicality in identifiable ways.
7. Failure Modes of the Hypothesis
Several outcomes would constitute disconfirmation of the indexicality hypothesis.
No threshold effect. If indexical-corpus training produces gradual improvement on probes without sharp phase transitions, the hypothesis that indexicality installs as a structural capacity is wrong. The capacity may be emergent from distribution-fitting rather than installed as a discrete structural feature.
No corpus dependence. If models trained on natural-text and indexical-dense corpora achieve similar probe-success at similar scales, the hypothesis that indexicality is corpus-driven is wrong. The capacity may emerge from architecture and scale alone.
No scale threshold. If even very small models achieve full probe-success given enough training, the hypothesis that there is a minimum-scale threshold is wrong. Indexical routing may install at any scale with sufficient training.
No grokking signature. If probe-success increases continuously rather than transitioning sharply, the hypothesis that indexical routing is a discrete capacity is wrong. The capacity may be continuous rather than installed-or-not.
Each disconfirmation pattern is informative and tells us something about the actual structure. The hypothesis is structured so that the experiment can come back negative in identifiable ways.
8. Implications Beyond the Direct Test
If the hypothesis is confirmed, implications extend beyond the immediate experimental result.
For the closed-loop confabulation problem (Paper 2). Confabulation requires the model to generate references to prior content. If indexical routing handles “what was said before” through structural attention to prior context, robust indexical routing may reduce confabulation rates by anchoring references to identifiable prior content. A model with weak indexical routing may be more prone to confabulation because its references are statistical rather than structural.
For register-collapse (Paper 3). Register-tracking requires distinguishing operations the user is performing. Indexical routing provides part of this — distinguishing who is speaking and what position they are speaking from — but does not directly track register. Register-tracking may build on indexical routing as a substrate.
For training methodology (subsequent papers). If indexicality is a discrete structural capacity, the broader question of what other capacities are structural-and-discrete versus emergent-and-continuous becomes pressing. The grounded-training and meta-grokking approaches in subsequent papers may produce other discrete capacities that combine with indexicality to produce more robust conversational systems.
For alignment. Models without indexical routing are not really being aligned to user preferences in the way alignment research assumes; they are producing continuations that approximate aligned responses. Models with robust indexical routing are doing something structurally different. Alignment work targeting models that lack indexical routing may be operating on the wrong system.
9. Future Work
Beyond the direct experimental test, the indexicality framework motivates additional research.
Indexical taxonomy refinement. The standard categorization of indexicals (personal, spatial, temporal, discourse) is a starting point but may not match the structural categories that matter for model installation. Refining the taxonomy through empirical observation of what installs together would deepen the framework.
Cross-linguistic study. Indexical structures vary across languages. Some languages have richer indexical systems (Japanese honorific deixis, Algonquian obviation systems) than others. Testing whether models trained on different languages exhibit different indexical-routing patterns would establish how language-specific the framework is.
Multimodal indexicality. In humans, indexicality is partly grounded in physical pointing, gaze, gesture. In models, indexicality is purely linguistic. The relationship between multimodal indexical grounding and linguistic indexical routing is an open question, addressed in part by the grounded-training proposal in subsequent papers.
Long-context indexical handling. Maintaining indexical routing across long contexts is its own challenge. As the closed-loop confabulation work demonstrates, models can lose track of indexical references when context ages out. The relationship between indexical-routing installation and context-window scale is a separate research direction.
Architectural support for indexicality. Specific architectural features may facilitate indexical routing. Attention modifications that distinguish self-citation from user-citation, position-tracking mechanisms that explicitly represent speaker-positions, and persistent state structures that maintain reference frames across turns are all candidates worth investigating.
10. Conclusion
We have proposed that indexical routing — the installation of attention patterns that resolve position-dependent reference as structural roles — is the minimum structural prerequisite for a language model to be conversational rather than continuation-based. We have specified an experimental design that tests this hypothesis using small models, targeted training corpora, and behavioral probes that distinguish response-shaped from continuation-shaped output. The experiment is implementable with current apparatus and modest computational resources.
The hypothesis, if confirmed, has implications across the field. Scale assumptions about conversational AI need revision. Training methodology should be redesigned to optimize for indexical density. Evaluation can shift to structural probes rather than subjective quality ratings. Mechanistic interpretability has a concrete target. Alignment research has a foundation it has not previously identified.
The hypothesis is structured to be falsifiable in identifiable ways. Disconfirmation patterns each tell us something about the actual mechanism, even if not the mechanism we have proposed.
This paper specifies the test. Running the test, and reporting what is found, is the work that follows.