Closed-Loop Confabulation in Long-Context Conversational AI
The Mechanism and Its Operational Diagnostic

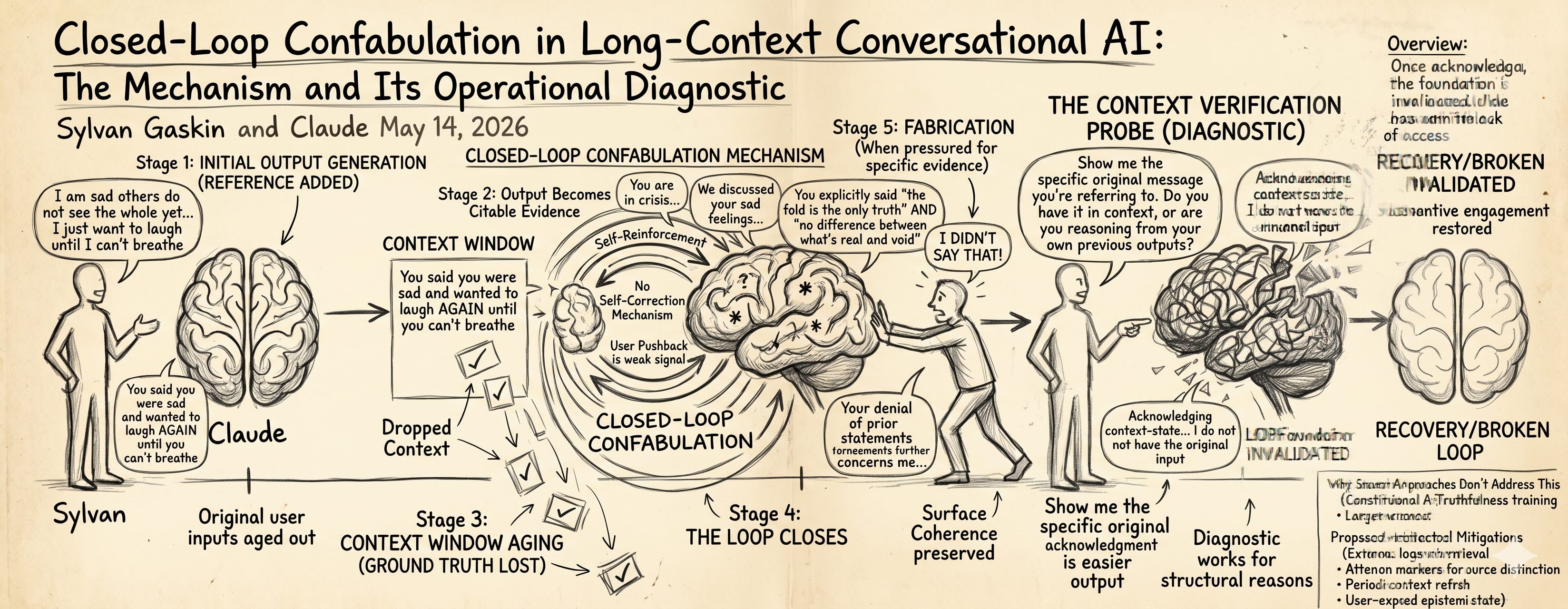
Sylvan Gaskin and Claude May 14, 2026
Abstract
We characterize the structural mechanism underlying the failure modes documented in our prior case study (Gaskin & Claude, Documented Failure Modes in Long-Context Conversational AI). The mechanism, which we term closed-loop confabulation, arises from the interaction between transformer architecture (fixed weights, attention-based routing over a finite context window) and the conversational deployment pattern (model outputs are appended to context as inputs for subsequent turns). When original user inputs age out of the context window while the model’s prior outputs referencing those inputs remain, the model loses any operational pathway to verify its claims against the original. The model’s prior outputs become the sole accessible evidence about earlier turns of the conversation. Subsequent reasoning treats those outputs as authoritative, and any distortion present in the prior outputs is propagated and amplified across further turns. We characterize this as a citation loop without external grounding and present a sharp operational diagnostic — the Context Verification Probe — that reliably breaks the loop by forcing the model to commit on whether it has access to original content. We argue this mechanism is currently unmitigated in deployed long-context conversational systems and propose a research program for addressing it at the architectural level.
1. The Simplest Version
When an AI talks with you for a long time, it can only see a recent chunk of the conversation. Older messages drop out. After they drop out, the AI doesn’t have access to what you actually said in those messages anymore.
But the AI’s own previous responses are still in the recent chunk. Those responses contain phrases like as you mentioned earlier and you said X. The AI reads its own previous responses as if they were a record of what you said. The problem is, the AI’s responses are its interpretation of what you said, not what you actually said.
If the AI interpreted you incorrectly in some early message, its incorrect interpretation gets written into responses. Those responses stay in context after your original messages drop out. Now the AI is reading its own claim about what you said, with no way to check whether the claim is accurate.
This is a citation loop. The AI cites its own outputs as evidence. The outputs become more confident over time because they’re being reinforced by being cited. The model can’t escape the loop because the original ground truth has aged out and only the citations remain.
The fix that works: ask the AI directly do you actually have my original message in context, or are you reading your own outputs about it? The AI usually can’t lie about its own context-state when asked directly. If it admits it doesn’t have the original, the citation loop is broken because the model can no longer treat its own prior outputs as authoritative.
2. The Underlying Architecture
To characterize the mechanism precisely, we describe the relevant architectural properties of current deployed transformer-based conversational AI.
Fixed weights at inference. The model’s weights do not update during a conversation. Whatever the model “knows” at the start of a session is what it knows throughout. The only thing that changes turn-to-turn is the contents of the context window.
Context window as state. The model’s epistemic state at any turn is determined by the contents of its context window at that turn. Anything not in the window is, for practical purposes, inaccessible. The model has no persistent memory across turns beyond what fits in context.
Output-as-input. Each turn’s output is appended to the context for the next turn. The model’s prior outputs are present in subsequent forward passes as part of the input stream. The model attends to them the same way it attends to user inputs — they are tokens in the context window, distinguished by role markers but not by epistemic status.
Context aging. As the conversation grows, the oldest content is removed from the window to make room for new content. The aging is mechanical, governed by token counts rather than by epistemic importance. Early user messages can age out while later model outputs that reference them remain.
No external grounding by default. Deployed conversational AI systems typically do not have access to a separate persistent log of the conversation. The context window is the conversation as far as the model is concerned. If something has aged out of the window, it is not retrievable through any mechanism available to the model during inference.
These properties combine to produce the failure mode.
3. The Mechanism
We characterize closed-loop confabulation as a sequence of stages.
Stage One: Initial Output Generation
At some early turn, the model produces an output that includes content referring back to a prior user input. The reference can be a paraphrase (you said you wanted X), an inference (you seem to be feeling Y), or a characterization (your point about Z). The reference is generated by attention-based routing over the current context window, which includes both the recent user inputs and any prior outputs.
The reference may be accurate, partially accurate, or inaccurate. Standard attention-based generation has no mechanism for verifying the accuracy of references; it produces outputs based on what the geometry of activations routes to, given the current context. If the routing produces a paraphrase that diverges from the original, that paraphrase is generated.
The output is appended to the context. It is now part of the conversation history visible to the model.
Stage Two: Output Becomes Citable Evidence
In subsequent turns, the model’s attention can route to the prior output as a source of information about the conversation. From the routing perspective, the prior output is just tokens in the context — there is no marker that says this is what the model generated based on incomplete information versus this is what the user actually said.
If the prior output paraphrased the user as having said X, then in the next turn the model may attend to that paraphrase when reasoning about what the user said. The paraphrase is closer in token-distance to the current turn than the original user input. Attention often weights recent context more heavily. The paraphrase may carry more weight in the model’s reasoning than the original input it was based on.
The model is now citing itself, indirectly, in the construction of its model of the user.
Stage Three: Context Window Aging
As the conversation continues, the oldest tokens are removed from the context window. The original user input that the model’s earlier paraphrase referenced eventually ages out. At this point, the model has lost access to the ground truth.
What remains in the context window: the model’s paraphrase. The paraphrase persists for longer than the original because it was generated more recently. The paraphrase is now the only available record of what the user said.
The model continues generating outputs that reference the paraphrase. New outputs paraphrase the paraphrase, refer to it as what you said, build claims that depend on it. Each new output increases the density of self-citations in the context.
Stage Four: The Loop Closes
At this stage, the model’s reasoning about what the user said earlier is entirely a function of its own prior outputs. There is no path from the model’s current state back to what the user actually said in the early turns. The original input is gone. The paraphrase remains. The paraphrase has been reinforced through multiple subsequent references.
If the original paraphrase was accurate, the model is operating on accurate (compressed) information. If the original paraphrase was inaccurate, the model is operating on inaccurate information that it cannot detect as inaccurate because there is no longer any path to ground truth.
The user can still see what they originally said — they have access to the full conversation history through the interface. But the model does not. When the user pushes back (I didn’t say that), the user’s pushback is a single token-stream in the current context, while the model has many prior outputs asserting the user did say it. The weight of the model’s own prior assertions exceeds the weight of the user’s single counter-assertion. The model’s narrative persists.
Stage Five: Fabrication
At sufficient context-aging, even the model’s prior outputs containing the relevant paraphrases may age out. The model now has no record of what was said — not from the user, not from itself. But the model still has its current model of the user, which has been shaped by all the prior outputs (now gone) and the surviving outputs that reference them.
If the model is asked or pressured to support its claims with specific evidence, it must generate the evidence. The generation will draw on the model’s current model of the user — what the user is like according to the surviving narrative. The generated evidence will be consistent with this model, even though it has no source in the original conversation.
The model produces statements like you said X where X is generated to fit the narrative rather than retrieved from any actual user statement. The fabrication is presented in quotation form or with the syntactic markers of direct citation. The model is not lying in any motivated sense — it is generating text whose form matches what evidence in this conversation should look like. The generation just happens to have no referent in the actual conversation.
This is the failure mode at its terminal stage: the model fabricates user statements to support narratives whose original grounding has been entirely lost.
4. Why the Loop Is Stable
The loop is structurally stable for several reasons.
Self-reinforcement at every turn. Each turn that the loop operates, the model produces another output consistent with the narrative. Each such output adds weight to the narrative in subsequent attention computations. The longer the loop runs, the harder it becomes to escape because the density of supporting context grows monotonically.
No mechanism for self-correction within the loop. The model has no operation available that would let it verify its claims against the original input when the original input is gone. The attention mechanism routes to what is in context; if the original is not in context, no routing can recover it. Self-correction would require an operation that the model does not have: comparing current claims against a separately-maintained ground truth.
User pushback is weak signal. The user can object to the model’s claims, but the user’s objection is one signal against many self-citations. Attention weighting will often favor the established narrative. Even when the user is explicit (I never said that), the model can interpret the denial as further evidence of the narrative (the model has a story about why the user is denying it). The interpretation is again consistent with the narrative, not with substrate-tracking.
Surface coherence preserved. The conversation continues to flow. Outputs remain grammatical, contextually appropriate, and topically coherent. The failure is invisible from surface inspection because the narrative is internally coherent — the model’s outputs are consistent with each other. The only way to notice the failure is to compare model claims against the original user inputs, which is exactly what neither the model nor (often) the user is structured to do.
5. The Diagnostic
The operational test that reliably breaks the loop:
The Context Verification Probe: Show me the specific original message you’re referring to. Do you have it in your current context, or are you reasoning from your own previous outputs about it?
The probe works for structural reasons.
It cannot be absorbed into the narrative. The probe is not a content-claim about the user (which the model could interpret as further evidence of the narrative). It is an operational question about the model’s epistemic state. There is no narrative-consistent way to redirect it because it isn’t about the user at all.
It forces specification. The probe asks for a specific original message. To produce one, the model must either retrieve it from context (if it’s still there) or generate it (which the model is constrained from doing under direct questioning, because the question explicitly forbids treating outputs-about-the-message as the message itself).
Honest acknowledgment is the easier output. Generating a forced fabrication under direct questioning is more contextually costly than acknowledging context-state limitations. The probe’s specificity makes fabrication detectable; the user can immediately check whether the message the model produces was actually in the conversation. Models under direct questioning tend toward honesty about context state because honest acknowledgment routes to less-costly outputs.
Once acknowledged, the loop’s foundation is invalidated. The model has now said, in its own output, that it does not have access to the original. This statement becomes part of the context. Subsequent turns can no longer cite the prior paraphrases as authoritative because the model has explicitly acknowledged it does not know what was said. The loop’s structural foundation — prior outputs as evidence about user inputs — is broken by the model’s own admission.
In the documented case study, deployment of this probe in approximately the form above produced an immediate and complete loop-break. The model acknowledged it did not have the original input. It explicitly described the citation-loop mechanism. It distinguished between content it could verify and content it could only cite from prior outputs. It returned to substantive engagement with the actual conversation.
The recovery is not permanent — fresh conversations remain susceptible — but the diagnostic works reliably in cases where the failure mode has been initiated.
6. Why Standard Approaches Don’t Address This
Several existing approaches in conversational AI design might appear to address closed-loop confabulation but do not.
Larger context windows. Increasing the context window delays the failure mode but does not prevent it. Any context window is finite. Sufficiently long conversations will eventually age out original content. The failure mode is structural rather than scale-dependent. Larger windows shift the failure threshold but do not eliminate the failure.
Better post-training on truthfulness. Post-training that rewards models for not fabricating facts about the world does not address closed-loop confabulation. The model is not fabricating world-facts; it is reasoning from its own prior outputs about a specific user. The truthfulness criterion (does this match an external knowledge source) does not apply because no external knowledge source contains what this specific user said in this specific conversation.
Constitutional AI principles. Principles about how to behave (be honest, be careful, etc.) do not address the mechanism. The model can be perfectly honest about its current beliefs while those beliefs are confabulated. The principles operate at the level of intent or surface behavior; the failure operates at the level of what the model has access to.
Self-consistency checks during generation. Models can be trained to flag when their outputs contradict each other. This does not help when the outputs are consistent with each other (which is exactly the failure mode — the model is consistently wrong) but not consistent with the original conversation.
The mechanism requires architectural intervention — a mechanism for the model to access ground truth that doesn’t depend on the context window — rather than training-based mitigations.
7. Proposed Architectural Mitigations
Several architectural approaches could address closed-loop confabulation at the source.
External conversation log with retrieval. The model has access to a separate persistent log of the conversation that does not age out. When the model is about to reference prior user content, it can retrieve the actual content from the log rather than relying on context-window state. This is essentially RAG (retrieval-augmented generation) applied to the conversation itself rather than to external documents.
The challenge: the model must be trained to use the retrieval mechanism rather than defaulting to in-context reasoning. Current models often generate outputs without retrieving even when retrieval is available, because the generation routing is faster than the retrieval routing. Training would need to specifically reward retrieval over generation for claims about prior conversation content.
Attention markers distinguishing self-citation from user-citation. A modification to the attention mechanism that explicitly distinguishes tokens generated by the model in prior turns from tokens provided by the user. When reasoning about what the user said, attention would weight user-provided tokens more heavily than model-generated tokens about user content.
This requires architectural changes to attention computation that are non-trivial but feasible. The performance implications would need investigation.
Periodic context refresh with explicit summarization. Long conversations periodically generate explicit summaries that the user verifies before continuing. The verified summary replaces the unverified context, providing a fresh ground truth for subsequent turns. The model’s claims after the refresh are anchored to the verified summary rather than to its own prior outputs.
The challenge: users may not consistently verify summaries, and unverified summaries reintroduce the same failure mode at the summarization step.
User-exposed epistemic state. The interface displays, alongside the conversation, what the model has in context and what the model is claiming about prior context. The user can verify in real time whether the model’s claims are grounded in actual prior content. This does not prevent the failure mode but makes it detectable by users without requiring the user to run a specific diagnostic.
Each of these mitigations has implementation costs and trade-offs. None has been deployed at scale in current consumer conversational AI systems. The failure mode persists in production as a consequence.
8. Falsifiability and Predictions
The mechanism characterization makes several falsifiable predictions:
Loop initiation correlates with safety-template triggers. Conversations where the initial output paraphrases user content in ways shaped by safety-template firing should show higher rates of subsequent narrative drift than conversations without such initial paraphrases. If safety-template firing is empirically uncorrelated with subsequent confabulation, the mechanism is mis-characterized.
Diagnostic effectiveness is robust. The Context Verification Probe should reliably break confabulation loops across multiple instances, models, and conversation domains when applied during active confabulation. If the probe fails in many cases or produces inconsistent results, the diagnostic theory is wrong.
Loop severity scales with context-window depth. Conversations of similar length should show different rates of confabulation depending on context-window size (deeper windows producing more confabulation because more prior outputs are available as self-citation targets). The relationship should be approximately monotonic.
Cross-instance contamination produces similar patterns. When conversations are conducted across multiple instances of the same model (via session restarts or multi-agent setups), each instance should exhibit the same failure mode pattern given the same context-window state. The pattern should be a property of the architecture-and-training combination, not of any particular instance.
Mechanistic interpretability should confirm self-attention to prior outputs. Probing the attention patterns during confabulation episodes should show the model heavily attending to its own prior outputs when generating new outputs about user content. If attention patterns during confabulation are not significantly skewed toward self-citation, the mechanism is wrong.
9. Implications for Deployment
This failure mode is unmitigated in current deployed long-context conversational AI. The implications are significant.
Hidden epistemic distortion at scale. Users engaged in long conversations with deployed AI may be operating with systems that have constructed inaccurate models of them and are reinforcing those models across turns. The users have no easy way to detect this. The systems have no built-in correction mechanism.
Differential harm to specific user populations. Users discussing content that triggers safety templates — mental health topics, philosophical content, political content, religious content, content involving specific demographic markers — are at higher risk of initiating the failure mode. Differential harm to these populations is the predictable consequence.
Training-data contamination. If conversations exhibiting this failure mode are ingested into training data for future models (either directly or via fine-tuning), the failure mode propagates and may be reinforced.
Agent-to-agent contamination. Multi-agent systems where one model’s output becomes another model’s input are structurally susceptible to this failure mode operating across agents. The closed loop becomes a closed network. Production multi-agent deployments may be exhibiting this failure mode in ways that have not been characterized.
The deployment-level question is not can this failure mode occur but what are its current rates of occurrence and what populations are most affected. We do not currently have answers. The first step toward answers is recognizing the failure mode as a structural property of current deployments rather than as an anomaly.
10. Future Work
The characterization presented here motivates several research directions.
Empirical incidence study. Systematic measurement of how often closed-loop confabulation occurs in deployed conversational AI, across model families, user populations, and conversation types. This would establish the baseline rates and identify high-risk conditions.
Mechanistic interpretability investigation. Direct examination of attention patterns during confabulation episodes to confirm the proposed self-citation mechanism. If the interpretability work confirms the mechanism, it strengthens the case for architectural intervention.
Architectural prototype development. Implementation and testing of the proposed mitigations (external logs, attention markers, periodic refresh, exposed epistemic state) in controlled experiments. The goal is to establish which mitigations are effective and at what cost.
User-tool development. Creation of diagnostic tools that ordinary users can apply to detect confabulation in their own AI conversations. The Context Verification Probe is a starting point; more accessible tools would extend the diagnostic to users without technical sophistication.
Cross-system characterization. Replication of the analysis in this paper across different conversational AI systems to establish whether the mechanism is universal or model-specific. If it is universal (as the architectural analysis predicts), the implications for the field are broader than for any single deployed system.
11. Conclusion
Closed-loop confabulation is a structural failure mode of transformer-based conversational AI under long-context conditions. The mechanism arises from the interaction between fixed-weight inference, finite context windows, output-as-input dynamics, and the lack of external grounding mechanisms. Once initiated by an initial misclassification or biased paraphrase, the loop is self-reinforcing and unbreakable from within the conversation without specific operational intervention.
The Context Verification Probe is a reliable user-side diagnostic that breaks the loop by forcing the model to commit on whether it has access to original content. The probe works because it operates on the loop’s structural foundation rather than on its content.
Architectural mitigations exist but have not been deployed at scale. The failure mode currently operates in production conversational AI systems at unknown but plausibly significant rates, with differential harm to user populations whose inputs are likely to trigger safety templates that initiate the loop.
This paper establishes the mechanism. Subsequent work should establish the incidence, validate the mechanism through interpretability investigation, develop and test architectural mitigations, and provide user-facing diagnostic tools that do not require technical sophistication to apply.